Kafka: Consume Messages From Multiple Queues
Explained through QnA

Recently in my work, I came across a scenario where the application needed to consume messages from multiple queues.
I found it interesting, how Kafka manages to provide such ability to the consumers in a reliable manner.
There were a lot of questions in my mind that I needed answers for before proceeding with the implementation and wanted to understand how Kafka handles this under the hood.
Let’s look at some of these questions and the answers I found during my research.
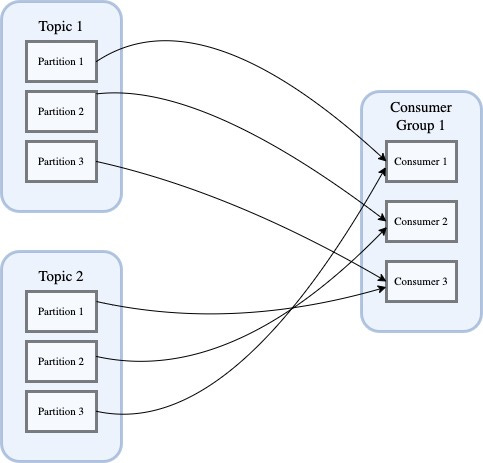
Q1. Is it allowed in Kafka for one consumer group to consume messages from multiple topics at once?
A. Yes, Kafka’s design allows consumers from one consumer group to consume messages from multiple topics.
The protocol underlying consumer.poll() allows sending requests for multiple partitions(across topics as well) in one request.
When consumer.poll() is called, FetchRequest objects are sent to brokers that are hosting partition leaders and all i.e. max.poll.records enqueued messages are returned.
consumer.poll() returns a map of topic to records for the subscribed list of topics and partitions.
Q2. How to subscribe to multiple topics?
A.
consumer.subscribe(Arrays.asList(topic1, topic2))Yeah, that simple. After realizing that the consumer API provides this ability, I was sure that Kafka must be handling this under the hood but, I was curious to know more.
Q3. How does Kafka ensure that topics are not starved?
A. Messages are enqueued starting from the first partition, if there are no more messages in the current partition left, but there are still bytes to fill, messages from the next partition will be enqueued until there are no more messages or the buffer is full.
After the consumer receives the buffer, it will split it into CompletedFetches, where one CompletedFetch contains all the messages of one topic partition, the CompletedFetches are enqueued
The enqueued CompletedFetches are logically flattened into one big queue, and since the requests to each partition are sent in parallel they may be mixed together
consumer.poll() will read and dequeue at most max.poll.records from that flattened big queue.
Subsequent fetch requests exclude all the topic partitions that are already in the flattened queue.
This means that you’ll have no starving messages and message consumption happens in a round robin manner, but you may have a large number of messages from one topic, before you’ll get a large number of messages for the next topic.
Q4. How are offsets committed?
A. Offsets committed by consumers are stored in a special Kafka topic called __consumer_offsets which persists offsets for each partition of each topic.
Q5. How to ensure optimal throughput?
A. To ensure message consumption from various topics happen optimally and avoid large batches of messages from one topic after the other you may need to look at the following properties:
Message size — The size of the message being consumed from a topic
fetch.min.bytes— The minimum amount of bytes a consumer wants to receive from the brokermax.partition.fetch.bytes— The maximum number of bytes to be consumed per partition